
Publication decisions for large language models, and their impacts
This post is one part of the sequence Understanding the diffusion of large language models. As context for this post, I strongly recommend reading at least the 5-minute summary of the sequence.
In this post, I:
- Overview the different forms of information and artifacts that have been published (or not) for the GPT-3-like models that I studied.
- Estimate some of the impacts of these publication decisions.
- Assess the different rationales for these publication decisions.
- Make predictions about how publication decisions and norms will change in the language modeling domain in the future.
Key takeaways
- My case studies suggest there is still a strong incentive for researchers at industry-leading AI labs to publish details about the training process, model architecture, and hyperparameter values they used. This has significant effects on diffusion. (more)
- I speculate that the rationale for publishing implementation details is to make research results more credible and easily verifiable. I think this is in turn desired due to (a) existing norms for research transparency and reproducibility, and (b) the incentive to attract top researchers, who tend to benefit from the transparency and reproducibility of the research they were involved in.
- I estimate (with 90% confidence) that disclosing all hyperparameter values for a GPT-3-like model saves between 1% and 20% of the total compute cost needed to replicate that model.
- EleutherAI based their choice of hyperparameter values on those of GPT-3. This seemed to shorten the duration of the GPT-NeoX-20B project—my best guess is a shortening of two weeks (90% CI: zero to six weeks).
- Compared to the implementation details, the code, datasets, and trained models from research were published much less or much later, and seemed to have smaller effects on diffusion even when published. These effects were significant, but I think that improving the publication practices of top developers (who are often the first to make advances in implementation) is a higher priority than preventing artifacts from being openly published after a long delay (more than 1 year). (more)
- I estimate that if code for training GPT-3 had been openly published beforehand, the production of EleutherAI’s GPT-NeoX-20B would have been sped up by two months (90% CI: one to six months), and Meta AI’s OPT-175B would have been sped up by two weeks (90% CI: one to six weeks). The difference is due to the gap between these actors’ talent resources (both experience and quantity).
- I estimate that the lack of access to large enough datasets, and code to process raw data into data suitable for training, delayed GPT-NeoX-20B by four weeks (90% CI: one to ten weeks). This is less than the delay due to code, because collecting and processing data seems easier than implementing efficient and bug-free training algorithms.
- Openly publishing the weights of a pretrained language model accelerates progress in that model’s performance on downstream tasks. This is because releasing the weights allows more people to experiment with different prompts and fine-tuning processes. However, openly publishing model weights probably did not significantly accelerate development of new, more advanced models in my case studies. Openly published GPT-3-like models arrived more than two years after GPT-3 was publicized. So top language model developers such as Google and DeepMind, who have developed models better than GPT-3 in the meantime, didn’t seem to benefit from this delayed open publication. Even if open publication came much sooner, I think that training new models would be more bottlenecked by access to compute and talent, not by knowing the weights of existing models.
- What is happening to publication strategies? (more)
- I’m 70% confident that, in each year from next year until transformative AI is developed, publication decisions by the top three language model developers (whoever they are, but currently Google, DeepMind, and OpenAI) will be more closed on average than they are now. This is due to the incentives for closedness prevailing as capabilities improve. The incentives for closedness that I have considered are (a) maintaining an advantage in capabilities, (b) protecting commercial IP, (c) avoiding regulation by reducing attention on capabilities, (d) reducing both societal and public relations risk from misuse of diffused artifacts.
- A key question is Google’s publication strategy going forward, as their decisions have varied a lot even in the past three years. But I’m still 65% confident that Google will openly publish fewer of their best-performing language models in the future than they do today.
- At the same time as actors like DeepMind and OpenAI adopt quite a closed publication strategy for GPT-3-like models, there is a reactive push for greater openness. This push is characterized by EleutherAI with GPT-NeoX-20B, Meta AI with OPT-175B, and BigScience with BLOOM.
- I expect this reactive diffusion dynamic will essentially continue for at least the next five years (with five years being a somewhat arbitrary time period). After five years, I think it’s more than 50% likely that this source of diffusion will be substantially reduced due to the occurrence of one of the following:
- The front-running actors will be so far ahead, and so incentivised not to publish, that no one else is able to diffuse their capabilities via replication.
- Even actors that keep up and diffuse models on purpose will decide that open publication of models has become too risky, given how powerful the state-of-the-art has become.
- I expect this reactive diffusion dynamic will essentially continue for at least the next five years (with five years being a somewhat arbitrary time period). After five years, I think it’s more than 50% likely that this source of diffusion will be substantially reduced due to the occurrence of one of the following:
Algorithmic details and hyperparameters were almost always openly published, despite this potentially reducing the compute barrier significantly

Table 1: Degree to which algorithmic details and hyperparameter values were disclosed for models in my case studies. See the diffusion database.
- Based on the data in the table above, there remains a strong incentive for researchers to specify details about the training process, model architecture,[1] and hyperparameter values.[2] This is even true of industry-leading AI labs, despite their incentive to protect commercial IP.
- I think that the disclosure of hyperparameters has a significant impact on diffusion, because finding good hyperparameter values can carry a computational cost that is a significant fraction of the total compute cost for a project. I estimate that disclosing all hyperparameter values for a GPT-3-like model saves 8% (90% CI: 1% to 20%) of the total compute cost needed to replicate that model. This means that in the case of GPT-3, I estimate the dollar cost saving (via reducing compute cost) to be $440K (90% CI: 68K to $1.6M). See appendix for details.
- Evidence of this cost saving in practice comes from EleutherAI, with the GPT-NeoX-20B model. They reportedly based their choice of hyperparameter values on those of GPT-3 “due to the intractability of performing a hyperparameter sweep for a 20-billion-parameter model.”[3] My best guess is that this decision shortened their project by two weeks (90% CI: zero to six weeks).
- I think that the disclosure of hyperparameters has a significant impact on diffusion, because finding good hyperparameter values can carry a computational cost that is a significant fraction of the total compute cost for a project. I estimate that disclosing all hyperparameter values for a GPT-3-like model saves 8% (90% CI: 1% to 20%) of the total compute cost needed to replicate that model. This means that in the case of GPT-3, I estimate the dollar cost saving (via reducing compute cost) to be $440K (90% CI: 68K to $1.6M). See appendix for details.
- Why is there such a strong tendency for publishing implementation details, even for industry labs? My best guess is that it’s mainly a combination of the following:
- There is an incentive to follow existing norms for research transparency and reproducibility.
- Transparency and reproducibility make the results more credible and easily verifiable to others, which in turn attracts more top research talent.
- Top AI researchers can more easily judge how impressive and interesting the research is when the implementation details are clear.
- I think these researchers also usually prefer their own work to be reproducible and credible to the wider AI research community, because those characteristics are a source of prestige in addition to merely showing impressive results, and researchers generally value prestige. As such, I think that researchers will be more inclined to work at a lab the more they expect their own work there would be transparent and reproducible, and that they’ll assess that partly based on the lab’s track record of making its work transparent and reproducible.
Training code, datasets, and models were mostly kept closed, but when published, they seem to have less impact on diffusion than publishing algorithm/implementation details
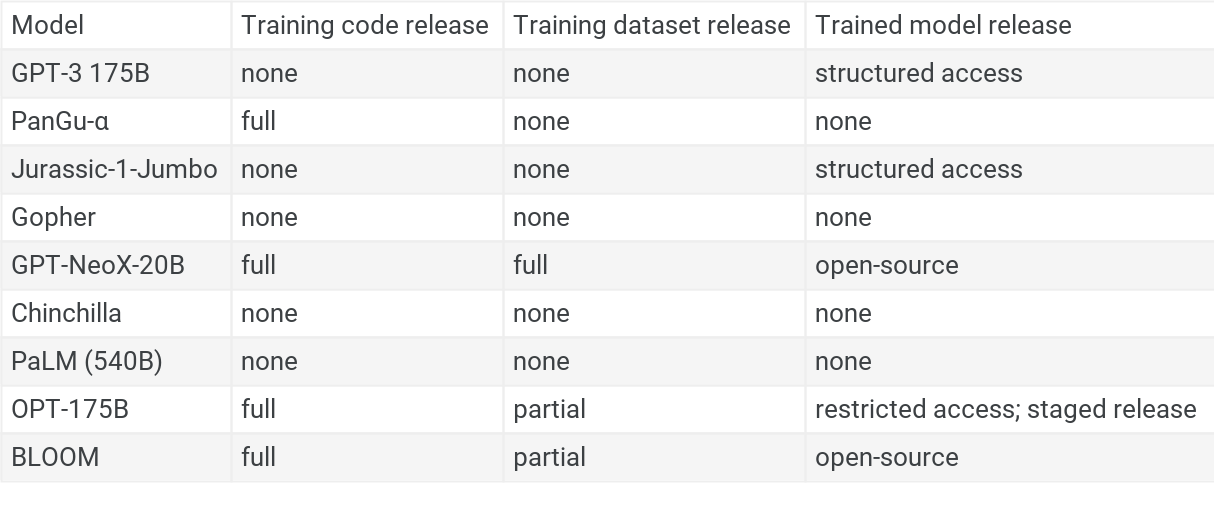
Table 2: Degree to which training code, training datasets, and trained models were released for models in my case studies. See the diffusion database.
Observations
- Compared to implementation details, code, datasets, and trained models are published much less in the cases that I studied. Referring to this section of the diffusion database, up until OPT 175B’s release in May 2022, I’m not aware of any GPT-3-like model that allowed direct access to trained model weights outside of the organization that developed the model. Five of the nine models I studied did not release the source code for training. And of the nine models I studied, only GPT-NeoX-20B fully released[4] the training dataset.
- The structured access approach adopted by OpenAI (in the form of the OpenAI API) has been emulated by other actors.[5] This includes an actor in China.
- Specifically, the structured access approach has been emulated by Inspur with Yuan 1.0,[6] and AI21 Labs with Jurassic-1-Jumbo (via AI21 Studio).
Counterfactuals & predictions
I’m highly uncertain about the effects of these individual publication decisions, but these are my best guesses:
- I surmise that open publication of the code for training GPT-3 would have sped up the production of GPT-NeoX-20B by two months (90% CI: one to six months).
- This is based on the GPT-NeoX GitHub repository starting in December 2020, and being worked on regularly for more than one year until the release of GPT-NeoX-20B in February 2022.
- Of course, there are many specific details of GPT-NeoX-20B that an existing openly published implementation would not have had. Among other things, they had to tailor their implementation to specific hardware. A researcher who has trained large language models at an AI safety lab told me: “Every company has somewhat different hardware setups/constraints, and it’s pretty important to be able to design your training around those constraints.”
- But given EleutherAI’s goal was to replicate GPT-3, I think that having the actual source code for GPT-3 (or similar) available would have saved a significant fraction of their total time spent on implementation (i.e., more than one month).
- Caveat: most contributors to GPT-NeoX-20B were far less than full-time, which makes these time estimates longer than would be the case for projects with full-time contributors.
- Given that Meta AI is part of a large tech company, they probably were not as reliant as EleutherAI on existing openly published code to train OPT-175B. But again, given that their goal was to replicate GPT-3, I expect openly published code could have sped up Meta AI’s OPT project by two weeks (90% CI: one to six weeks) given that their logbook spans about 11 weeks.
- I expect that the openly published training code for GPT-NeoX-20B, OPT-175B, and BLOOM will help many academic and independent researchers with training large language models. But I’m 90% confident that delayed open publication of training code speeds up future large language model releases by the top language model developers (Google, DeepMind, OpenAI, Microsoft, Anthropic) by no more than one month. The decision to openly publish code for a new state-of-the-art result is much more important than code to train an existing model that gets published one year or more after the model. This is because those top developers already had their own private codebases that serve a similar purpose to the openly published implementations. If code was openly published after GPT-3 that implemented major efficiency improvements that were novel even to a top developer, then that would be significant. But in my case studies, I haven’t seen strong enough evidence that openly published implementations had a significant impact on the speed of top developers.
- My best guess is that the lack of access to large enough datasets, and code to process raw data into data suitable for training, delayed GPT-NeoX-20B by four weeks (90% CI: one to ten weeks).
- The best evidence I have for this is EleutherAI’s work on The Pile (Gao et al., 2020). Data deduplication alone took “several days,” which suggests to me that the full process of producing the dataset took at least one order of magnitude more time.[7] However, the cost of producing a dataset like this seems to be orders of magnitude lower than the compute requirements—EleutherAI created The Pile without any funding or sponsorship, unlike the training of GPT-NeoX-20B.[8]
- EleutherAI’s own dataset, The Pile, then subsequently diffused to Meta AI, as a subset of the Pile formed a subset of the training dataset for OPT-175B.[9] So the open publication of The Pile may have sped up OPT-175B by more than one week. But this is not completely clear—other datasets were used in the full training dataset, and sometimes using open-source software or data unexpectedly causes more trouble than it’s worth.
- I’d guess that the wider access to a GPT-3-like model offered by OPT-175B, and the open publication of BLOOM, will counterfactually speed up language model performance on downstream tasks by 0.5 months (90% CI: zero to two months). In contrast, I think wide access to these models will not significantly affect progress on more foundational capabilities (e.g., few-shot learning) that improve via pre-training with more compute and data.
- I think that the wide access to these models, and the cheapness of running them compared to training them (see this section of a previous post), will enable at least twice the output of relevant research than before.[10] Every trained model has its own behavioral quirks, and probing a new model to understand these quirks could provide new insight. Things like prompt engineering can improve a lot by testing the model on different prompts (Liu et al., 2021). Some actors could also afford to try different fine-tuning datasets and techniques, since this costs less than training the original model from scratch.
- One reason that the counterfactual impact is not larger is because wide access has been (or will be) granted to other models soon after the release of OPT-175B and BLOOM (this already happened with GLM-130B in August 2022).
- Another reason the counterfactual impact is not larger is because model APIs already seem to serve a large fraction of use-cases for researching model behavior. GPT-3-like models don’t seem radically different from each other, so researching BLOOM (for instance) is not likely to provide a big new insight compared to researching GPT-3 using the OpenAI API.
- Still, direct access to model weights removes restrictions on the model’s rate of output and on the way that the model can be fine-tuned. (As an aside, direct access also enables some forms of interpretability research.)
- I expect that the pace of progress in foundational capabilities afforded by pretraining on more compute and data will not be significantly affected by these openly published models. This is because researching the behavior of these models does not seem relevant to the challenges of scaling up compute and data. Scaling up compute and data mostly requires engineering talent, access to compute, and access to data. And I think that scaling up compute and data will most likely be the key drivers of future improvements to pre-trained language models (see this section of a later post).
Rationales for release strategies vary, and include commercial incentives, misuse concerns, and a reactive push for openness

Table 3: Summary of rationale for release strategies for different models. Click through to the diffusion database for sources and reasoning (which is the basis for my claims in the text that follows, unless stated otherwise). For context, it’s helpful to review the information on the release strategies themselves in the previous section (or just view all the columns side-by-side in the database).
Observations
In the cases where models were not released, the apparent incentives included protection of commercial IP, as well as concerns about the misuse and harm that could be driven by diffusion. On the misuse side, it is notable that three of the leading AI developers (if not the three leaders)—Google, DeepMind, and OpenAI—have all based publication decisions partly on misuse concerns.
A key question is Google’s publication strategy going forward. I’m more uncertain about this than for DeepMind and OpenAI. To my knowledge, DeepMind has a comparatively strong history of closed publication (there are notable exceptions, such as AlphaFold, but that was openly published years after the system was first publicized). OpenAI was historically more open, but has made a clear turn to closedness in recent years with GPT-2, GPT-3, and DALL-E. Meanwhile, the teams working on AI at Google seem to be more mixed in recent years:
- Google’s pretrained 11-billion-parameter T5 model was openly published in October 2019 (as GPT-2’s prominent “staged release” strategy was ongoing) (Raffel et al., 2019; Clark et al., 2019).[11]
- To my knowledge, October 2020’s G-Shard model has not been openly published (Lepikhin et al., 2020).
- The Switch Transformer model, published about in January 2021 (Fedus et al., 2021), was openly published.
- Some code for September 2021’s FLAN model was openly published, but not the trained model itself, as far as I know.
- The LaMDA model, publicized in January 2022, has not been released (Thoppilan et al., 2022).
- The PaLM 540B model, publicized in April 2022, has not been released (Chowdhery et al., 2022).
When I asked Iulia Turc (former Software Engineer at Google Research) about the rationale for not releasing model weights, data, code, etc. for the language models they knew about at Google, they told me: "Ethical concerns were the single most important reason (that's why LaMDA hasn't been released yet). I know this can sometimes sound like PR, but I do think that everyone in my management chain was genuinely worried [about] generative models falling into the wrong hands. Google is very skeptical of including generative models even in its own internal products."
At the same time as actors like DeepMind and OpenAI are adopting a more closed publication strategy for GPT-3-like models, there is a reactive push for greater openness.
- This push is characterized by EleutherAI with GPT-NeoX-20B, Meta AI with OPT-175B, and BigScience with BLOOM. In their publications about these models, these actors emphasized the value of providing wider access to large models, especially to academic or independent AI researchers, for the sake of making research more responsible. In EleutherAI’s case, there was also an apparent interest in accelerating empirical AI safety research on the largest language models.
- The push for openness is in explicit reaction to the closed publication strategy of other actors. For example, the OPT paper says “[The] restricted access has limited researchers’ ability to study how and why these large language models work, hindering progress on improving known challenges in areas such as robustness, bias, and toxicity.” The BLOOM announcement blog post says “academia, nonprofits and smaller companies' research labs find it difficult to create, study, or even use LLMs as only a few industrial labs with the necessary resources and exclusive rights can fully access them. Today, we release BLOOM […] to change this status quo” (BigScience, 2022).
In between the concerns about misuse and the push for openness, are middling cases like Jurassic-1-Jumbo. AI21 Labs did not openly publish the Jurassic-1-Jumbo code or trained model weights. However, their stated rationale for making a model API available was along the lines of accelerating AI development and democratizing access to AI technology. The API release could be mostly explained by commercial interest, but that may not fully explain the fact that the API is free to use at an entry level for anyone who signs up.[12]
A general point to emphasize here is that publication strategies vary a lot, and that’s because publication incentives vary a lot. There are several different incentives that cumulatively influence publication decisions:
- An incentive in favor of publication is that credible demonstrations of capability attract talent, funding, or users. Other incentives are prestige, the desire to get extra benefits once one has paid the cost of doing the research, the default norm for openness, the ability to influence AI development (in place of someone else who would publish next), and the societal benefits of the work.
- Incentives against publication are the desire to protect IP to preserve a commercial or research advantage, avoiding regulation by reducing attention on capabilities, wariness of societal harms from use of the model, and the norm to not publish artifacts/work that potentially make development of further AI advances easier (given those advances may be risky).
As an example of how these incentives lead to specific publication decisions for specific actors, consider NVIDIA’s Megatron model (which was not part of my case studies). NVIDIA openly published the code for the Megatron model but did not release the trained model weights. As noted in Shelvane (2022, p. 42), releasing the code is in NVIDIA’s commercial interest: the code helps and encourages people to train language models on NVIDIA hardware. In contrast, releasing the model does not seem to benefit NVIDIA, and may have even harmed their commercial interests by saving some people the trouble of training their own model.
For another example, AI21 Labs’ business is in providing trained AI models as a service. So it seems best for AI21 Labs not to openly publish their models, but it’s in their interest to attract customers by making their model API free to use at the entry level, and discover improvements and new applications by seeing how the API is used.
Predictions
- I’m 65% confident that in the future, Google’s best-performing language models will get less publication on average. To clarify, I’m talking about the trained models themselves, not research papers. My confidence is above 50% due to (a) the quote from Iulia Turc in the previous section, (b) the apparent commercial incentives for protecting IP becoming stronger as models become more expensive and powerful, and (c) the most recent models, PaLM and LaMDA, not being released. However, the mixed historical data in the previous section makes me quite uncertain, and thus my confidence is only somewhat above 50%.
- I expect that a reactive openness dynamic like we are seeing today in the language modeling domain will continue for at least the next five years. (The five-year window is somewhat arbitrary—I chose it for the sake of concreteness.) This in turn is based on the following predictions:
- [70% confidence] There will remain at least one AI developer that keeps up with the state-of-the-art and is motivated to diffuse capabilities on purpose over the next five years. “Keeping up with” means being able to match state-of-the-art language modeling results within one year. Meta AI is one such potential actor, though they took about two years in the case of matching GPT-3.
- [80% confidence] There will continue to be a set of lower-resourced actors that are frustrated by their lack of access to state-of-the-art models. This frustration will create enough demand that, if claim (a) is also true, a higher-resourced actor would decide to be generous to them or become convinced that their demands are valid and it's right to meet them.
- I expect this frustration because I expect there will continue to be a large gap between the front-running AI developers and other actors. I quantify the gap as a lead of more than two years on the ability to produce the state-of-the-art model at a given time. I’m currently agnostic about the exact sets of actors that are divided by this gap over time, because that seems more difficult to predict.
- But I think it’s more than 50% likely that after five years, either:
- The front-running actors will be so far ahead and so strongly incentivised not to publish that no one else will be able to diffuse their capabilities via replication. The incentives will exist for similar reasons to today’s, which were discussed earlier.
- Even the actors that keep up and were diffusing models on purpose will decide that open publication of models has become too risky, given how powerful the state-of-the-art models have become.
- As a corollary of the reasoning in point 1 and point 3: I’m 70% confident that publication decisions by the top three language model developers will become more closed on average, from now on.[13]
- There are potential self-interested reasons for greater openness of publication—namely, to improve one’s reputation, and to allow new insights to be found independently and shared back to the original publisher. But I think that the value of maintaining an advantage in capabilities, and of protecting commercial IP (in the case of industry labs, which currently lead the state-of-the-art), will prevail over those incentives for openness.
Appendix: estimating cost saved on replication by knowing hyperparameter values
- How does hyperparameter selection work for GPT-3-like models? Based on that, how much of the total compute cost to produce a GPT-3-like model is for hyperparameter selection? My best guess is 8% (90% CI: 1% to 20%) of the total compute cost.
- A common method to find good hyperparameter values is to run multiple trials of training the model.[14] Each of these trials may have a much smaller number of examples than the final training run, to save computation. Based on how the model performed in the trials, the model developer chooses the hyperparameter values that are expected to give the best performance.
- My impression is that the machine learning research community has by now gathered many heuristics for choosing good hyperparameter values. For example, the batch size and learning rate values used for GPT-3 were informed by previously obtained empirical data and empirical relationships.[15] These heuristics can greatly reduce computational cost compared to running large searches over possible hyperparameter values.
- But even with heuristics and prior knowledge about good hyperparameter values, my impression is that some expensive tests and searches are typically required. For example, several different learning rate values may need to be tested on a significant fraction of a full training run to be confident enough that the final training run will succeed.
- A researcher who has trained large language models at an industry AI lab told me: “[The] principal way hyperparams get tuned for large models is by running many experiments on smaller models and looking for a pattern. [The] total cost of the entire process is maybe 10%? Definitely more than 1%, definitely less than 30%.”
- After weighing up the above considerations, evidence from one expert, and my own intuition, my best guess is that the compute cost of finding good hyperparameter values for a new GPT-3-like model would make up 16% (90% CI: 3% to 40%) of the total compute cost.[16]
- How much of the total compute cost of replicating GPT-3 was counterfactually saved by the hyperparameter values being published (as well as parts of the hyperparameter selection process)? My best guess is 8% (90% CI: 1% to 20%) of the cost.
- If GPT-3 hyperparameter values were not published, then other published hyperparameters for similar models probably would have sped up the search.
- However, other hyperparameter settings would probably be further from optimal. Training dynamics can be quite sensitive to hyperparameters.[17] For example, the learning rate could be too large and cause training to become unstable. So even with the next-best hyperparameter settings available, some experimentation would probably be warranted for some hyperparameters such as the learning rate and batch size.
- To account for the counterfactual, I halve my 90% CI to span from 1% to 20% of the total compute cost of replication.
- In a previous post, I estimated the total compute cost of OPT-175B (which replicated GPT-3) at $6M (90% CI: $4M–$10M).
- So in dollars, I estimate that hyperparameter tuning for replicating GPT-3 would cost $440K (90% CI: 68K to $1.6M). See this Guesstimate model for the calculation.
Acknowledgements

This research is a project of Rethink Priorities. It was written by Ben Cottier. Thanks to Alexis Carlier, Amanda El-Dakhakhni, Ashwin Acharya, Ben Snodin, Bill Anderson-Samways, Erich Grunewald, Jack Clark, Jaime Sevilla, Jenny Xiao, Lennart Heim, Lewis Ho, Lucy Lim, Luke Muehlhauser, Markus Anderljung, Max Räuker, Micah Musser, Michael Aird, Miles Brundage, Oliver Guest, Onni Arne, Patrick Levermore, Peter Wildeford, Remco Zwetsloot, Renan Araújo, Shaun Ee, Tamay Besiroglu, and Toby Shevlane for helpful feedback. If you like our work, please consider subscribing to our newsletter. You can explore our completed public work here.
- ^
Machine learning models can be thought of as a mathematical function. The parts of the function that are learned during training are the weights (AKA parameters). The parts of the function that remain fixed constitute the model architecture. For example, in Transformer models, the self-attention operation is part of the model architecture, but the weights used in that operation are not. See Bloem (2019) for more information about the Transformer architecture.
- ^
Hyperparameters are parameters that control how a model learns. For example, the learning rate hyperparameter controls the magnitude of changes in weight values at each training step, and affects the stability and speed of training. There are hyperparameters associated with the training algorithm (such as the learning rate), and hyperparameters associated with the model architecture (such as the number of layers).
- ^
See Black et al. (2022, p. 3). Note that GPT-NeoX-20B does not meet my definition of a GPT-3-like model, but I think the point about saving cost is still applicable to larger models.
- ^
The datasets for OPT-175B and BLOOM draw from other datasets which are publicly available, but the final full dataset has not been made available for either model.
- ^
See Shelvane (2022). From the Abstract: “Structured access [is where] instead of openly disseminating AI systems, developers facilitate controlled, arm's length interactions with their AI systems.”
- ^
Credit to Jeffrey Ding and Jenny Xiao for finding this case
- ^
See Gao et al. (2020, p. 27)—at the end of the “Deduplication” section it says “In the end, we ran in-memory LSH on a machine with enough RAM for Common Crawl, taking several days.”
- ^
See Biderman et al. (2022, p. 6)—“This dataset was created by individuals working on their own time without funding.”
- ^
See Biderman et al. (2022, p. 2): “The pre-training corpus contains a concatenation of datasets used in RoBERTa (Liu et al., 2019b), the Pile (Gao et al., 2021a), and PushShift.io Reddit (Baumgartner et al., 2020; Roller et al., 2021).”
- ^
This is just a claim about research quantity rather than quality or usefulness.
- ^
See Raffel et al. (2019): “To facilitate future work on transfer learning for NLP, we release our data set, pre-trained models, and code.”
- ^
As an aside, Shelvane (2022, p. 42) noted that AI21 Labs previously “trained a GPT-2-like model and bowed to OpenAI’s [GPT-2] release schedule, even though they did not agree that the risks of GPT-2 warranted this. This was out of ‘respect for our colleagues who have thought hard about these issues.’” AI21 Labs has since collaborated with OpenAI on "Best Practices for Deploying Language Models."
- ^
The choice of top three is a somewhat arbitrary number for the sake of concreteness—I’m not sure what the best threshold is, but three seems like a reasonable number to hedge between one actor getting far ahead vs. many actors keeping up with each other.
- ^
- ^
See Brown et al. (2020, p. 9): “As found in [KMH+20, MKAT18], larger models can typically use a larger batch size, but require a smaller learning rate. We measure the gradient noise scale during training and use it to guide our choice of batch size [MKAT18].”
- ^
I started with a prior based on my intuition of 35% (90% CI: 10% to 80%). I interpreted the expert’s view as 10% (90% CI: 1% to 30%). I then weighted the expert’s view to my own at 3:1 (taking a weighted average of the central estimate and each bound individually).
- ^
This is based on my own experience with machine learning, and reading various machine learning papers.